Высоконагруженный сервис по парсингу социальных сетей
Высоконагруженный сервис по парсингу социальных сетей.
Клиент обратился к нам после того, как система перестала справляться с обработкой данных: сервера отказывали в обслуживании при превышении нагрузки в 50 одновременных пользователей. От нас требовалось повысить мощность системы и взять на себя технические работы по развитию проекта на основе roadmap заказчика.
За 2 месяца мы перенесли весь проект на новые мощности. Через месяц по результатам анализа мониторинга мы подкорректировали парк серверов, внеся изменения в аппаратную часть.
КлиентБизнес заказчика построен на анализе данных в социальных сетях (группы, сообщения, репосты, лайки и прочее).УслугиРазработка архитектуры, Перенос на новую архитектуру, Создание документации, Back-end администрирование, Разработка, Нагрузочное тестирование, Настройка мониторинга и уведомлений, Техническая поддержка, Развитие проектаГод2017ГородСанкт-ПетербургТехнологииAngular, JQuery, PHP, Yii2, Java 8, Apache TomCat 7, MySQL, MongoDB, RabbitMQ
Цель проекта
Сделать процесс анализа данных в социальной сети простым и понятным
Задачи проекта
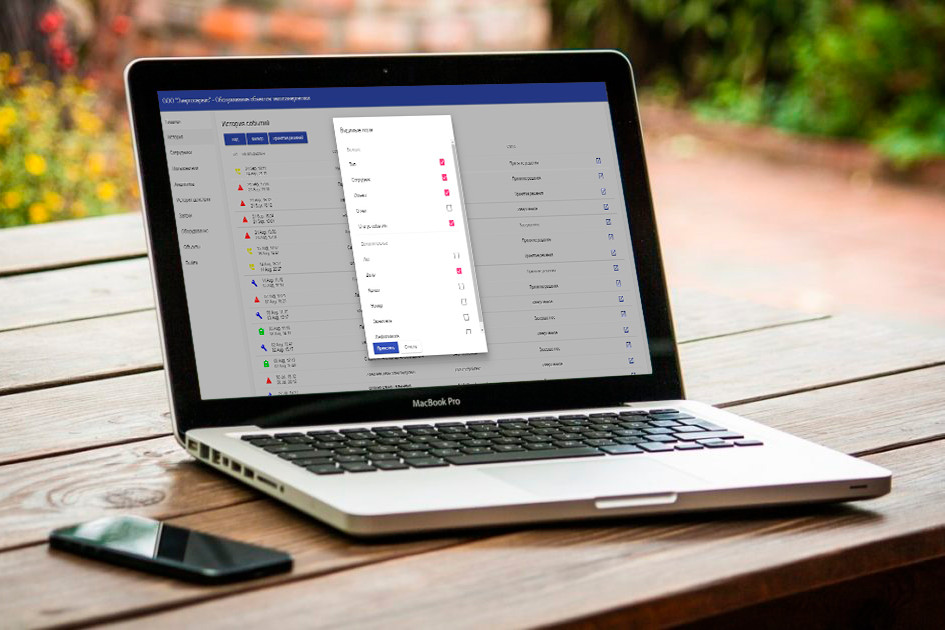
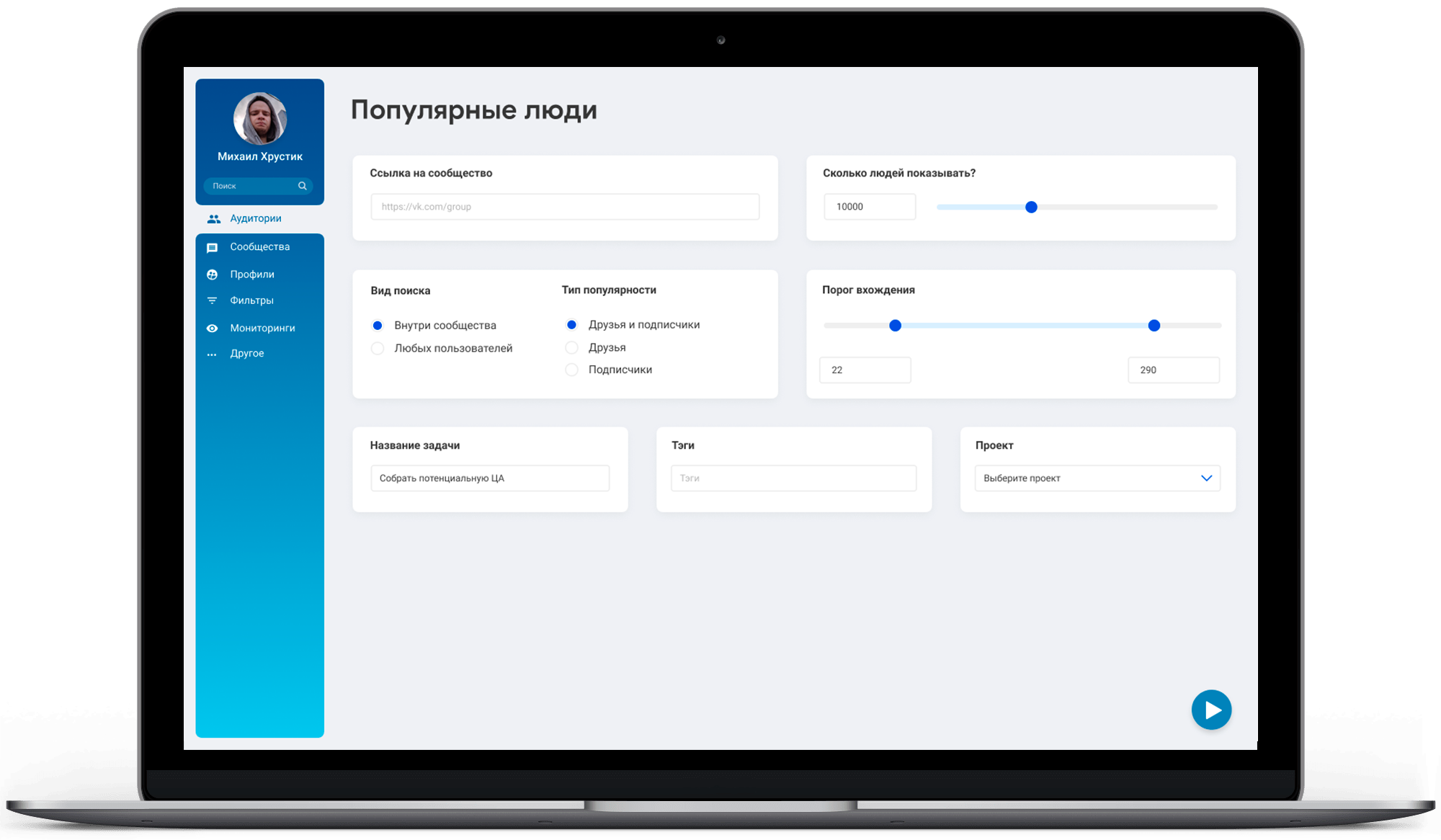
Создание инструмента аналитики данных:
- Сделать так, чтобы текущее решение (созданное второй командой) заработало при нагрузках более 50 пользователей
- После вывода системы в рабочий режим продолжить развивать систему по согласованному с заказчиком Roadmap
Решение
Система аналитики данных, способная выдерживать большие нагрузки
Команда на проекте
Проектировщик
Дизайнер
Архитектор
Front-end разработчик
Back-end разработчик
Техлид
DevOps инженер
Менеджер проекта
Тестировщик
Ход проекта
Разработали новую архитектуру программы и серверов, которая позволяла неограниченно масштабировать программу
1 нед
Разработали план переноса кода со старой архитектуры на новую в соответствии с техническим заданием, которое было к тому моменту готово и осуществили переезд.
2 мес
Запустили beta-тестирование системы на 1 сервере на 100 лояльных пользователях заказчика. Система успешно справилась с beta-тестированием.
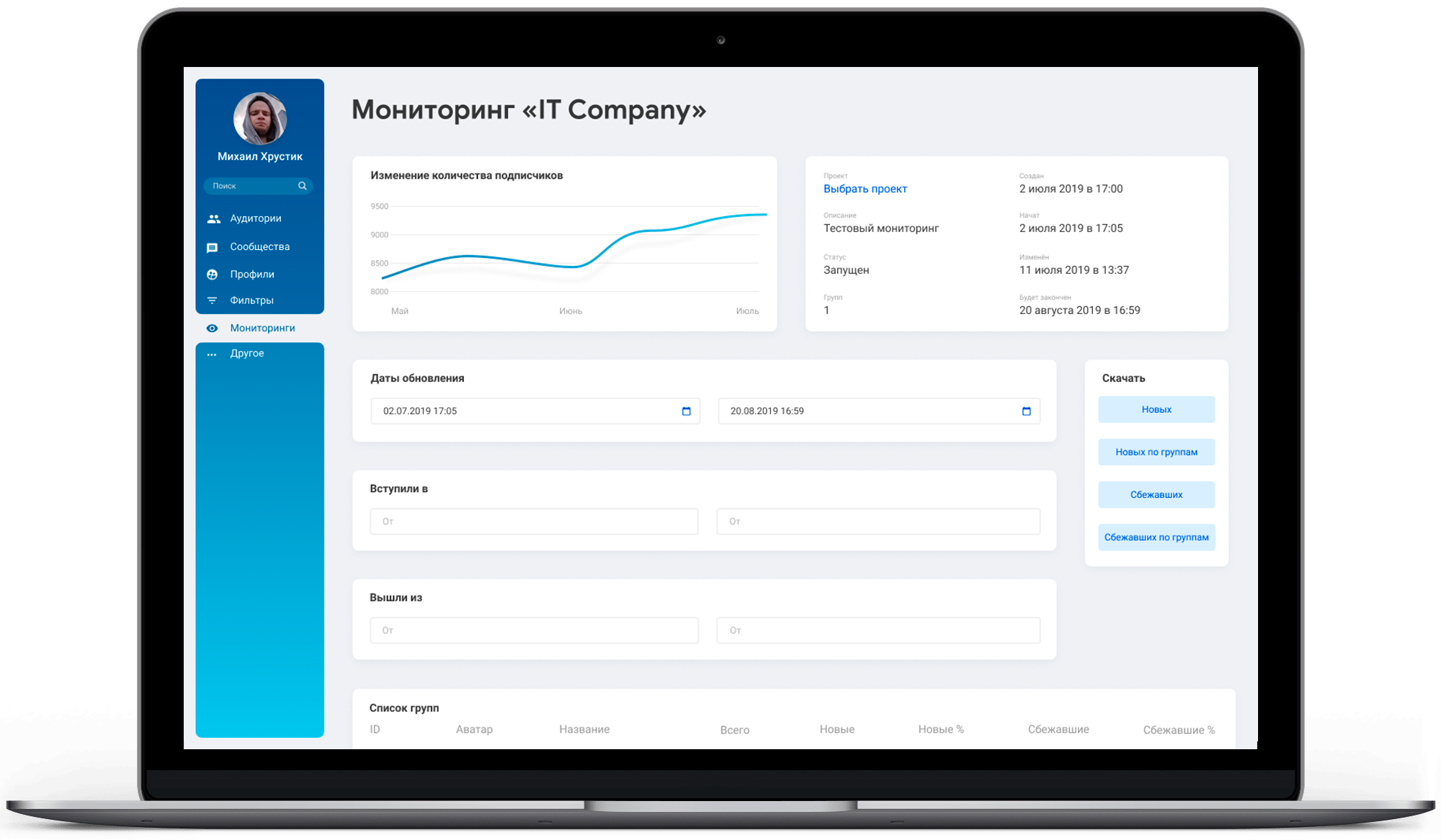
Во время тестирования мы сделали замеры нагрузок во время тестирования. Рассчитали предполагаемую нагрузку при выводе на 10 000 человек и подобрали необходимый парк серверов по техническим характеристикам, который, с одной стороны, решал задачу технической нагрузки, с другой, был выгодным для заказчика.
Развернули парк за 2 недели и запустили на всех пользователях за 2 недели
Параллельно настроили систему Grafana для мониторинга состояния каждого сервера. Мониторинг снимал более 100 метрик по каждому серверу в реальном времени.
Настроили Telegram-уведомления о подозрительном поведении сервера. Если какая-то из характеристик приближалась к критическому порогу, мы получали предварительное уведомление в Telegram.
Через месяц по результатам анализа мониторинга мы подкорректировали парк серверов, внеся изменения в аппаратную часть. Изменения были направлены, прежде всего, на снижение стоимости серверов, во вторую очередь – на повышение производительности.
Параллельно с этим мы разрабатывали и внедряли новые функциональные модули согласно планам клиента.
Результат
Высоконагруженный сервис по парсингу социальных сетей
Лендинг
Личный кабинет моряка
- Создание резюме
- Подбор релевантных вакансий
- Отклик на вакансию
Личный кабинет крюинга
- Создание профиля компании
- Размещение вакансий
- Прием откликов на вакансию от соискателей
Личный кабинет администратора
- Модерация профилей моряков
- Модерация крюингов и вакансий
- Управление отображением информации на лендинге
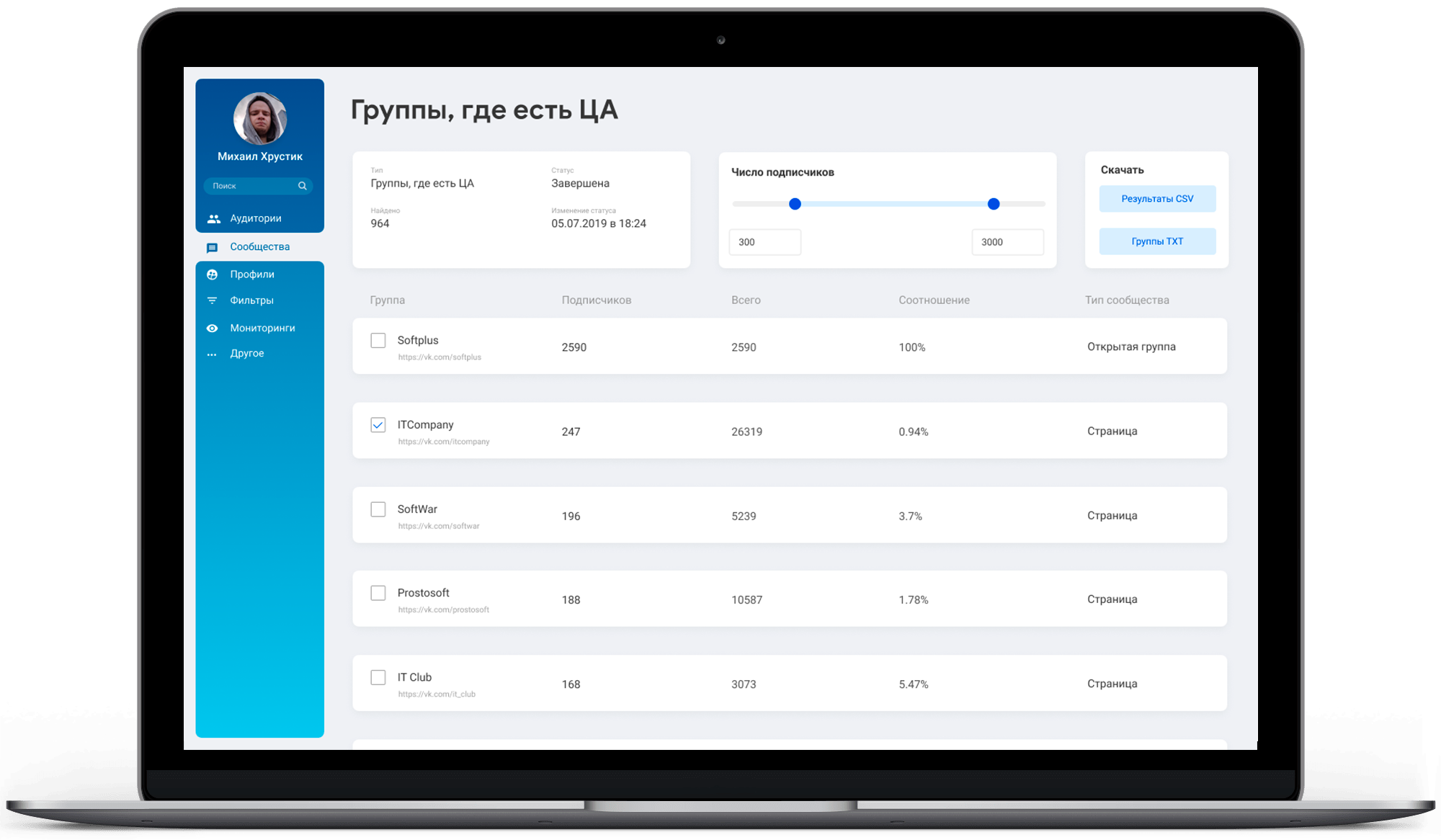
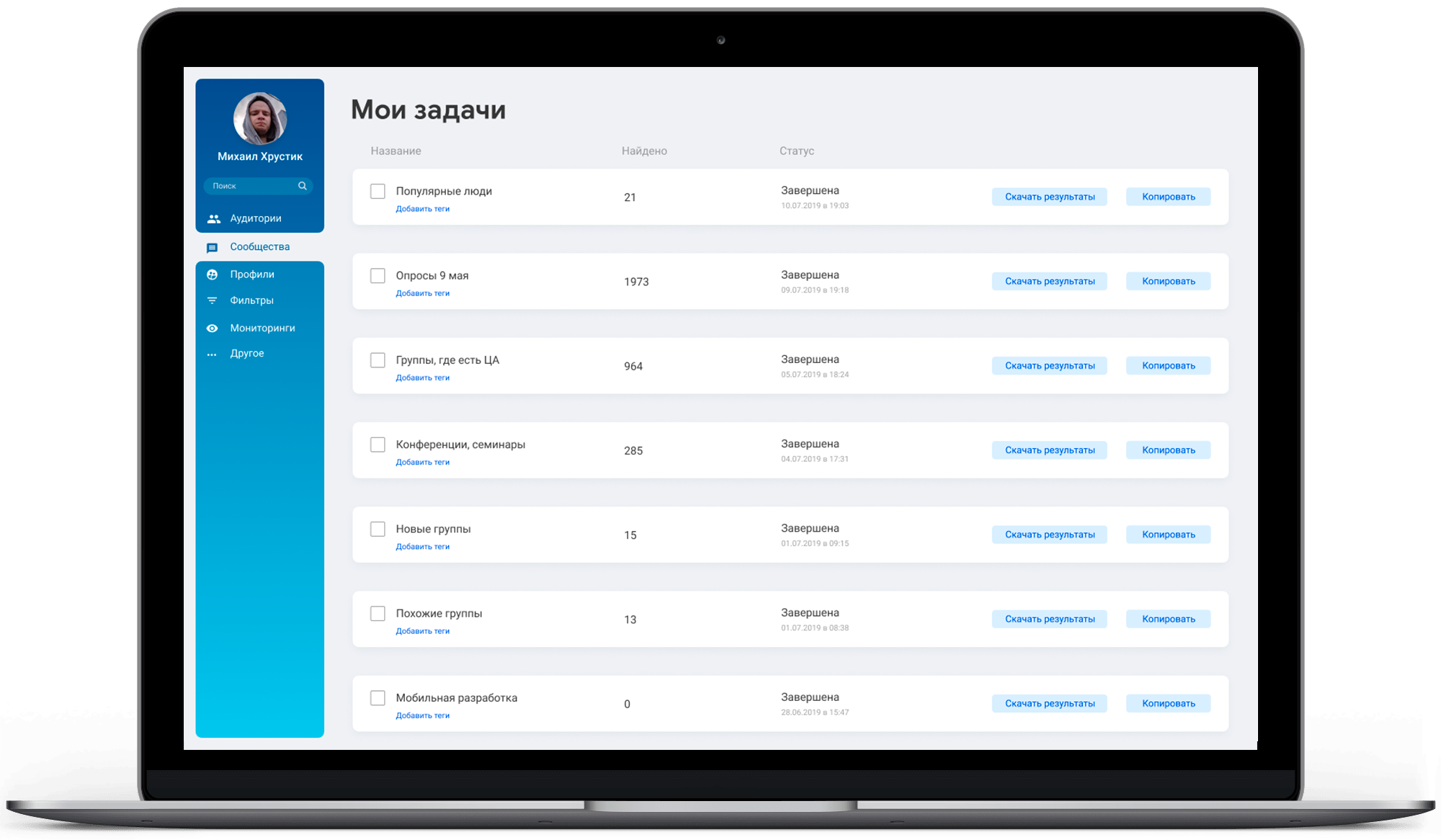
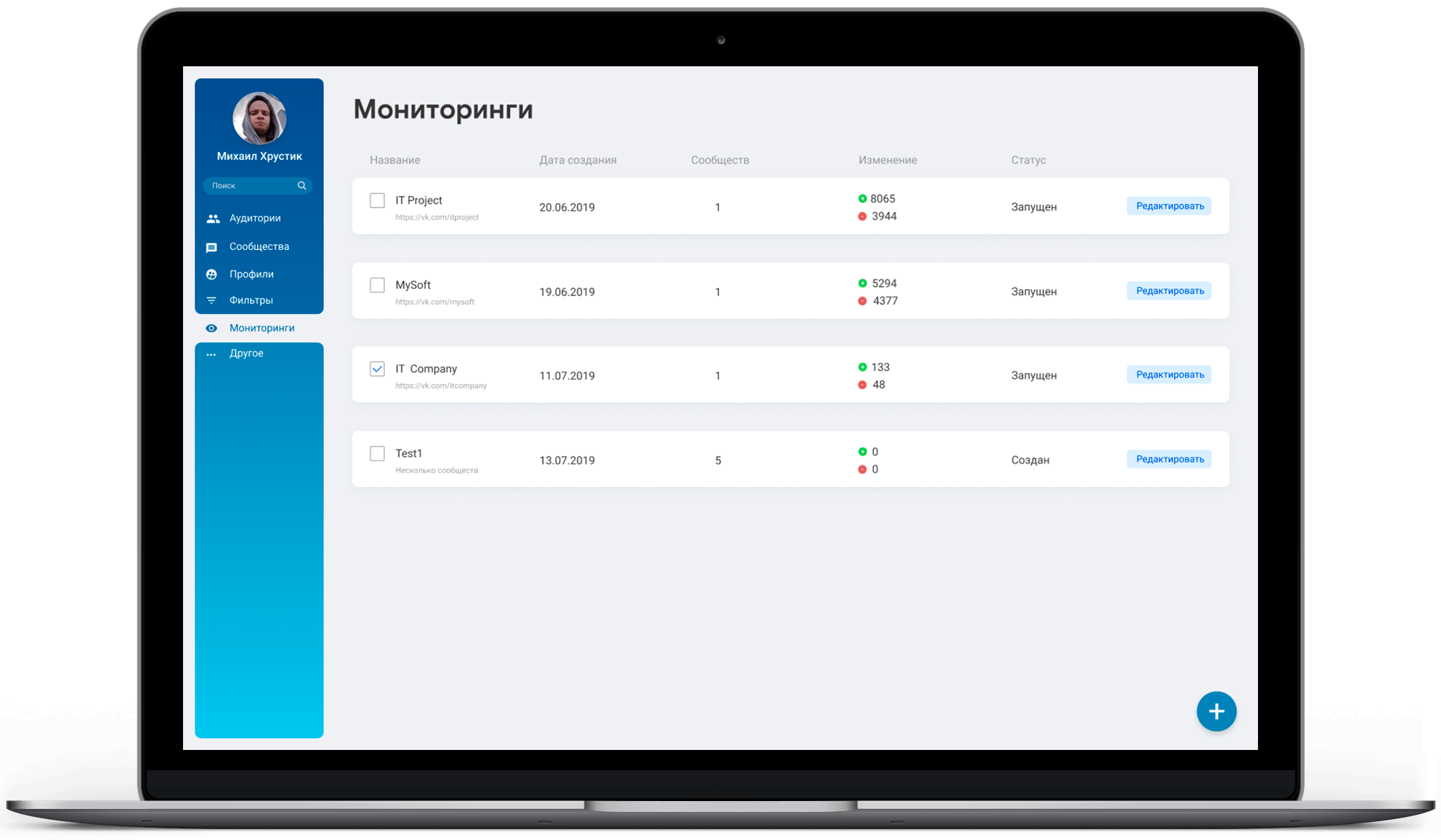
Особенности проекта
Система работает на 7 собственных серверах
Самые мощные сервера оснащены процессорами суммарно в 40 потоков и 256 Гб ОЗУ
Возможность горизонтального масштабирования под нагрузкой
Логика обхода блокировки серверов
900 статистических анализов в день
В случае выхода из строя одного из серверов второй продолжает обслуживать запросы клиентов
Постоянный мониторинг каждого сервера с автоматическими уведомлениями о критических событиях
За сутки обрабатывается в реальном времени порядка 500-800 Гб данных
Подробное описание архитектуры
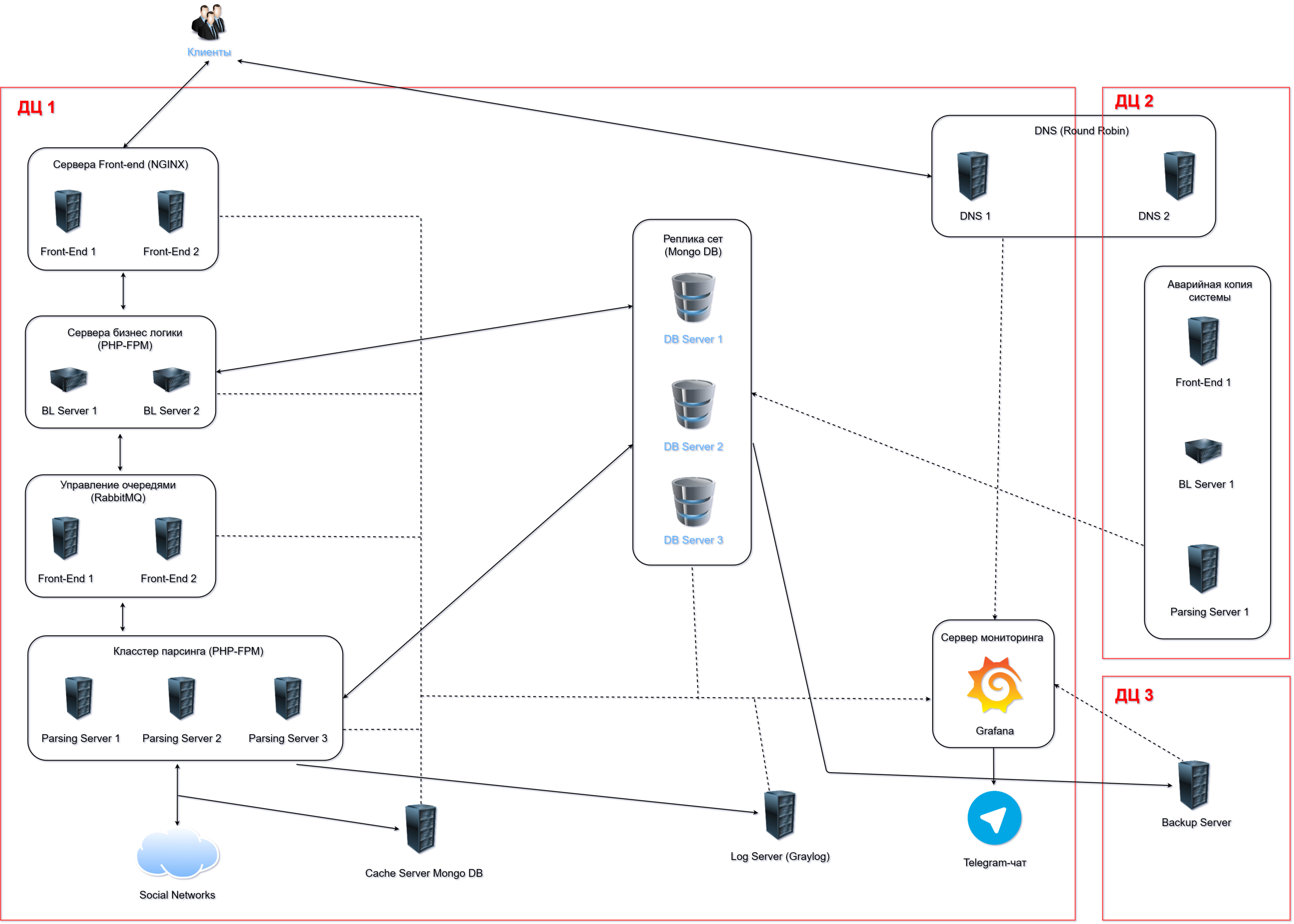
Клиенты заходят на страницу приложения в браузере. Браузер отправляет запросы на один из двух front-end серверов. Наличие второго front-end сервера повышает комфорт работы за счет лучшего времени отклика системы, увеличивает общую отказоустойчивость: в случае выхода из строя одного из серверов второй продолжает обслуживать запросы клиентов. За распределение запросов между серверами отвечает сервер DNS 1.
Front-end сервера перенаправляют запросы на сервера бизнес-логики БЛ. Их тоже два для повышения отказоустойчивости. Если запрос относится к данным, которые были раньше собраны, то сервер бизнес логики выполняет его, используя данные хранящиеся в Replica Set. Если же запрос касается сбора новых данных, то БЛ сервер отправляет его на аналитику в кластер парсинга. Т.к. кластер парсинга обычно сильно загружен (load average 88%), запросы серверов БЛ ставятся в очередь в блоке Queue Management, который регулирует нагрузку на сервера парсинга.
Сервера парсинга собирают данные из социальных сетей и производят над ними сложные аналитические операции с большими объемами данных (порядка 109 строк), используя базы данных Replica Set. Результат аналитики сохраняется в Replica Set. Один анализ может длиться от нескольких секунд до нескольких недель.
Для того чтобы сократить это время, используется Cache Server, который кэширует запросы к социальным сетям.
На log-сервере ведется журнал работы всех серверов. На сервер мониторинга собираются метрики производительности и состояния всех серверов системы. В случае приближения к критическим порогам отправляются сообщения в Telegram-чат.
Все данные Replica Set непрерывно архивируются на Backup Server, который находится в удаленном дата-центре.
Если в дата-центре 1 (ДЦ 1) произойдет что-то страшное, например, пожар, то у системы есть возможность в течение пяти минут переключиться на работу в дата-центр 2 (ДЦ 2), в котором развернута упрощенная копия архитектуры дата-центра 1 (ДЦ 1).
Для того чтобы дата-центр 2 (ДЦ 2) был всегда готов к внезапному приему нагрузки, ключевые данные из дата-центра 1 (ДЦ 1) непрерывно синхронизируются с дата-центром 2 (ДЦ 2) (лаг 2 минуты).
Общий объем хранилища Replica Set 60 TB. На нем хранятся данные только актуальных аналитик (за последние 30 дней). Более старые данные переносятся на back-up-сервер в дата-центр 3 (ДЦ 3), в котором хранятся данные всех анализов с 2015 года.